Blog / data engineering
Dev Note #01: reconstruyendo futbol-analitico (desde el extractor)
Primer avance del refactor de futbol-analitico: scraping, modelo base, auditoría y fallback multi-fuente para la poderosa Liga 1.
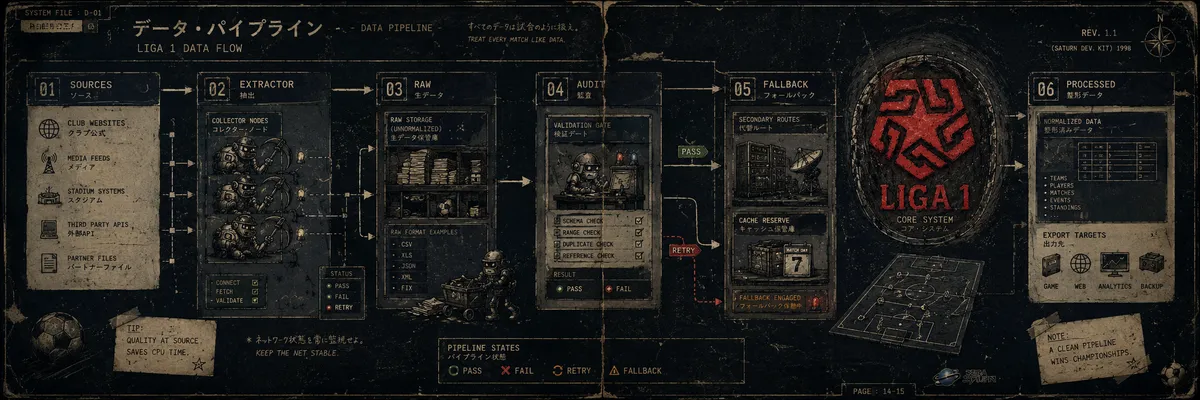
Una de las razones por las que armé retropipeline.dev fue para no dejar mis proyectos personales tirados en una carpeta con nombres tipo final_final_ahora_si_v2, como si eso alguna vez hubiera terminado bien. Y dentro de esa lista de cosas que no quería abandonar estaba futbol-analitico: mi intento de construir un proyecto de datos sobre la Liga 1 de Perú sin depender de una API paga, sin vender un riñón y sin fingir que el fútbol peruano tiene la misma cobertura estadística que la Premier League.
Después de varias semanas medio disperso, decidí retomarlo con una idea más clara. Ya no quería que fuera solo un conjunto de notebooks exploratorios con containers alrededor para sentirme más ingeniero de datos de lo que la situación realmente ameritaba. La idea ahora era empujarlo poco a poco hacia algo más serio: un proyecto reproducible, auditable y con una base lo suficientemente decente como para construir análisis encima sin estar mintiéndome a mí mismo. La pregunta inicial de esta primera fase fue bastante simple:
¿puedo construir una base confiable de partidos y estadísticas de la Liga 1 de Perú sin depender de una API paga?
Por ahora, la respuesta es: sí, pero con varios asteriscos. Porque claramente nada relacionado a recopilar data de fútbol peruano podía ser tan sencillo como “corre el script y ya”.
Qué construí en esta primera fase
El primer objetivo fue armar el core de extracción. Nada demasiado glamoroso todavía. Antes de pensar en dashboards, métricas bonitas o conclusiones tácticas con cara de hilo de Twitter, necesitaba resolver lo básico: obtener partidos, resultados y estadísticas de forma más o menos consistente. Para eso elegí PromediosInfo como fuente principal. La página permite obtener el fixture por jornadas y, en varios partidos, también acceder al detalle estadístico. No es una fuente perfecta, pero para empezar tenía algo importante: estructura suficiente para scrapear sin tener que hacer rituales oscuros cada vez que quería sacar una jornada. Con eso ya se generan dos modelos base:
fct_match: una fila por partido, con fecha, jornada, equipos, marcador, estado del partido y tarjetas.fct_team_match: dos filas por partido, una por equipo, con estadísticas como remates, posesión, pases, faltas, córners y tarjetas.
Sé que los modelos todavía son básicos y que esta no es la parte sexy del proyecto. Nadie arma una presentación diciendo “miren mi tabla intermedia, qué hermosa cardinalidad”. Pero antes de hablar de tendencias, estilos de juego, rendimiento o cualquier cosa que suene más interesante, necesitaba asegurarme de que la base inicial tuviera sentido. Porque si la data nace mal, cualquier dashboard encima solo va a verse bonito mientras miente. Y para mentiras bonitas ya tenemos suficiente con las promesas de pretemporada de algunos clubes.
El primer problema real: la fuente no siempre está completa
Durante las pruebas apareció el primer golpe de realidad: PromediosInfo no siempre trae estadísticas válidas para todos los partidos. Hasta ahí, nada sorprendente. El problema fue que la ausencia de data no siempre aparecía de forma limpia. No era tan amable como decirte “oye, acá no tengo estadísticas, no me uses”. Ojalá. Encontré dos casos principales:
- Partidos donde el bloque de estadísticas existe, pero todos los valores aparecen en cero.
- Partidos donde directamente no existe el bloque de estadísticas.
El segundo caso es molesto, pero al menos es honesto. Si no hay bloque, no hay mucho que discutir. El primero es el realmente peligroso, porque un cero puede parecer un dato válido. Y si lo aceptas sin revisar, terminas creyendo que un equipo no remató, no tuvo posesión, no hizo faltas y básicamente jugó como si hubiera mandado once conos a la cancha. Podría pasar en la Liga 1, no voy a hacerme el loco, pero igual había que validarlo. De ahí salió una regla importante para el proyecto:
No todo cero es un dato. A veces es simplemente una ausencia mal disfrazada.
Y esa regla parece pequeña, pero cambia bastante la forma de tratar la extracción. Porque ya no basta con leer una tabla y guardarla. También hay que preguntarse si esa tabla realmente está diciendo algo o si solo está rellenando espacio como alumno que estira una conclusión para llegar al mínimo de palabras.
Fallback con BeSoccer
Para no depender por completo de una sola fuente, probé BeSoccer como fuente secundaria. La idea no fue reemplazar PromediosInfo. No quería convertir esto en una pelea de fuentes ni empezar a mezclar data sin control como quien junta excels en una carpeta llamada “consolidado bueno”. La idea era más simple: usar BeSoccer solo cuando la fuente principal fallara o trajera estadísticas sospechosas. Después de revisar su estructura, encontré que BeSoccer expone las jornadas mediante un endpoint AJAX y que las páginas de detalle tienen un bloque de estadísticas bastante útil. No diría que fue elegante, pero funcionó. Y a veces en scraping eso ya es bastante, porque uno entra buscando ingeniería y termina negociando con HTML como si estuviera intentando leer jeroglíficos mojados. Con ese fallback pude recuperar estadísticas para partidos donde PromediosInfo no tenía datos confiables. Por ahora, el flujo queda así:
- PromediosInfo se usa como fuente principal.
- Si PromediosInfo trae estadísticas válidas, se conservan.
- Si PromediosInfo no trae estadísticas o trae placeholders en cero, se intenta recuperar el partido desde BeSoccer.
- El resultado final conserva trazabilidad de la fuente usada.
Ese último punto es importante. No quiero que el pipeline se haga el vivo y esconda de dónde salió cada cosa. Si una estadística viene de PromediosInfo, perfecto. Si viene de BeSoccer porque hubo fallback, también perfecto, pero tiene que quedar marcado. Después, cuando algo no cuadre, al menos sabré a quién culpar primero. Esto permitió completar una primera versión del extractor sin barrer los problemas de calidad debajo de la alfombra. Y eso, para un proyecto que recién está dejando de ser experimento, ya es un avance bastante decente.
Auditoría de calidad
También implementé una primera auditoría reproducible. No es la parte más vistosa del proyecto, pero sí una de las más necesarias. La auditoría revisa cosas básicas como:
- que cada partido tenga el número correcto de filas en
fct_team_match; - que haya una fila local y una visitante;
- que los goles coincidan entre
fct_matchyfct_team_match; - que los remates al arco no superen los remates totales;
- que la posesión tenga rangos razonables;
- que no existan partidos con todas las estadísticas en cero.
Son controles simples, sí. No estoy reinventando la ingeniería de datos ni descubriendo una nueva partícula subatómica. Pero son el tipo de validaciones que te evitan construir una torre encima de una base chueca y luego preguntarte por qué todo se fue al suelo. La lógica es bastante directa: si la auditoría falla, no tiene sentido construir visualizaciones encima. Primero se arregla la base; después se piensa en gráficos. Porque si no, terminas con un dashboard precioso, con colores lindos, filtros elegantes y conclusiones completamente podridas por dentro. Y no gracias. Ya bastante daño hacen algunos gráficos de barras en reuniones eternas.
Estado actual
La primera versión del extractor ya está funcionando. Actualmente el proyecto puede correr:
python scripts/run_extract.py
python scripts/run_audit.pyLa extracción genera archivos intermedios en data/interim/ y la auditoría genera reportes en data/audit/. Todavía no considero esto una versión analítica completa. De hecho, sería medio vendehumo decirlo. Lo veo más como una primera base sólida: un extractor reproducible, con fallback, trazabilidad de fuente y controles mínimos de calidad. No es la parte más espectacular del proyecto, pero sí es la que evita que todo lo demás nazca torcido. Es como poner los cimientos antes de decorar la sala. Aburrido, sí. Necesario, también.
Qué sigue
El siguiente paso será construir la capa normalizada. Eso implica:
- normalizar nombres de equipos;
- crear IDs canónicos;
- generar una capa
curated; - ordenar columnas y tipos de datos;
- dejar la base lista para métricas derivadas.
Recién después de eso vendrá la parte más interesante: crear métricas por equipo, analizar forma reciente, comparar localía, volumen ofensivo, posesión, disciplina y otros patrones de rendimiento. Ahí el proyecto debería empezar a sentirse más como análisis de fútbol y menos como estar peleándome con tablas, fuentes incompletas y ceros sospechosos. Aunque, siendo honestos, probablemente me siga peleando con todo eso, solo que con nombres de carpetas más bonitos. Por ahora, el avance importante es poco glamoroso, pero necesario: futbol-analitico ya dejó de ser solo exploración y empezó a comportarse como un pipeline real. Todavía falta bastante, pero al menos ya hay algo sobre lo que construir sin sentir que estoy levantando una casa encima de arena mojada. Que, considerando que hablamos de data de la Liga 1, ya es más de lo que esperaba en esta primera vuelta.